- 1. 前言
- 2. 语法章
- 3. 数据结构章
- 4. 集合框架篇
前言
本系列文章将分为三部分:
Java基础篇
- 语法篇
- 数据结构篇
- 集合框架
Java高级篇
- JVM知识
- 多线程
- Java IO
- Java安全
- 设计模式
Java实践篇
- 并发编程相关
- 分布式相关
- 框架介绍
有些【疑问】可能会留在笔记中,在学习中补充…
相关链接
- javase 1.8 online doc
- javase 1.7 online doc
- javase 1.8 JVM Specification online doc
- javase 1.7 JVM Specification online doc
语法章
手动编译Java工程
目前的代码打包工具很多,前有ant,后有Maven, Gradle, SBT, Ivy, Grape…,手动编译运行,是怎样的。这里简单举个例子,假如文件组织如下:
src/
- classes/
- a.java
- b.java
- test/
- main.java(import classes)
- classes/
编译java文件
1javac a.java b.java main.java- 无顺序之分
- 生成的class文件默认在原目录
- -s 能指定编译结果要置于哪个目录(directory)
运行
进入src目录12// -cp: 等价于-classpath,多个则用分号;分开,也可带上jar包java -cp . test.main
于是,当需要对工程进行编译,则需要先编译好,在打包时,为了能带上环境变量,往往把包路径移至import的那一层,然后打成war包或jar包等。
数组常用操作
填充
1234int test[] = new int[4];int testDeep[][] = new int[4][5];// 仅限一维Arrays.fill(test, 8);打印
1234// [8, 8, 8, 8]System.out.println(Arrays.toString(test));// [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]System.out.println(Arrays.deepToString(testDeep));拷贝
12345678910int test_copy[] = new int[test.length];System.arraycopy(test, 0, test_copy, 0, test.length);test[0] = 9;// [8, 8, 8, 8]System.out.println(Arrays.toString(test_copy));int[] test_copy_v2 = Arrays.copyOf(test, test.length);test[0] = 10;// [9, 8, 8, 8]System.out.println(Arrays.toString(test_copy_v2));
效率:
System.arraycopy > Arrays.copyOf(本质上新建了数组,并调用了前者) > for循环赋值
构造函数
- 类中的普通方法可以和类名同名,和构造方法唯一的区分是,构造方法没有返回值;
- 抽象类可以有构造方法,接口中不能有构造方法。
类的继承
方法的重写(override),两同两小一大原则:
- 方法名相同,参数类型相同
- 子类返回类型小于等于父类方法返回类型,
- 子类抛出异常小于等于父类方法抛出异常,
- 子类访问权限大于等于父类方法访问权限。
程序中代码的加载顺序
假设在主函数中new一个子类构造函数,执行顺序为:
- 父类B静态代码块->子类A静态代码块->父类B非静态代码块->父类B构造函数->子类A非静态代码块->子类A构造函数。
- 静态代码块和静态变量的加载看书写顺序;
原因:涉及类加载过程中初始化顺序,详看【高级篇】
静态类
静态类只能是内部类,可以被继承
继承需要注意的
子类定义了父类没有的方法,而用父类指向子类对象,不能直接调用子类方法,需要强制转换:
例子
- 父类构造函数调用自己的方法,若子类继承其方法,则运行时调用的是子类的方法,如下输出为null,纵使Sub是静态内部类:1234567891011121314151617181920public class Base {private String baseName = "base";public Base() {callName();}public void callName() {System.out.println(baseName);}static class Sub extends Base {private String baseName = "sub";public void callName() {System.out.println (baseName) ;}}public static void main(String[] args) {Base b = new Sub();}}
包访问权限
类似C++中的friendly,不过还是有人吐槽,包访问权限就是个鸡肋的存在。主要有几个要点:
- 对于其它包类,该成员为private;
- 继承者与被继承者都处于同一个包才能访问包访问权限成员;
接口与抽象类
抽象类的修饰符可以为public或abstract
123// 以下合法,public和abstract都可以abstract interface InterfaceTest {}内部接口修饰符还可以protected,private
12345public class TT {private interface KL{public void teset();}}接口可以继承接口,不可以继承类
123// 接口可以继承接口,不可以继承类interface CallableStatement extends PreparedStatement{}接口的成员特点:
1234567891011121314public interface Inteface1 {void sayHello();String name = "enjoyhot";}class Enjoyhot implements Inteface1{public void sayHello() {// TODO Auto-generated method stub}}// enjoyhotSystem.out.println(Inteface1.name);
成员变量: 只能是常量。默认自动添加(也只能是)修饰符
public static final
成员方法: 只能是抽象方法。默认自动添加(也只能是)修饰符
public abstract
内部类:自动地(也只能是)修饰符
public static
内部类
可声明为public,然后在外部调用:
1父.子 test = 父.new 子();内部类操作可直接引用外部类域(包括private),内部类可以直接访问外部类属性,包括private修饰的属性,可通过类似MyOuterClass.this的操作来获得外部类的引用;
- 内部类是一种编译器现象,JVM毫不知情;值得注意的是,当内部类调用外部类的私有域时候,编译器将产生一个static方法,该方法具有包访问权限,因此就提供给黑客一个修改私有域方法的切入点:-D;
- 在内部类不需要访问外部类对象时,应使用静态内部类,这样该内部类就不能随意访问外部非static域,达到安全的目的,否则如上点,自动转为static方法;
局部类
例子
12345678910111213141516public class LocalClass {{class AA{}//块内局部类}public LocalClass(){class AA{}//构造器内局部类}public static void main(String[] args){}public void localClass(){class AA{}//方法内局部类}public static void main(){}}//编译后,形成诸如:外部类名称+$+同名顺序+局部类名称//LocalClass$1AA.class LocalClass$2AA.class LocalClass$3AA.class LocalClass.class特点
- 局部类的修饰符一定是包权限;
- 此时不能访问外部类域,访问外部调用的参数需要声明为final,编译后该final局部变量为该内部类的final实值域;
- 原因:假如只是外部传递过来的普通变量,调用外部方法后,这个变量将因返回而释放内存消失,这时就会出现内部类引用非法。而用final修饰后,编译器会在内部类中生成一个外部变量的拷贝。
- 总结而言,封闭的作用域引用了外部变量必须定义为final,在做spark的MapReduce操作时经常会遇到。网上一个应用例子如图所示:

自动拆箱装箱
自动装箱和拆箱从Java1.5开始引入,将int的变量转换成Integer对象,这个过程叫做装箱,反之将Integer对象转换成int类型值,这个过程叫做拆箱。装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。
| byte | short | char | int | long | float | double | boolean |
|---|---|---|---|---|---|---|---|
| Byte | Short | Character | Integer | Long | Float | Double | Boolean |
- 举例说明
|
|
- i01和i02相比将自动拆装箱,数值相比; // 那究竟是拆还是装【疑问】
- i01和i03比的是地址(在编译前定义的数值一般会从常量获取,除了valueOf操作需要值的范围-128~127(1字节)才是从常量中获取,为什么【疑问】),i01和i03都是编译之前定义的,所以是常量池中的同一个对象;
- i03和i04比较的是地址,因为i04是编译之后又new出来的对象,所以它的地址必然不在常量池中,所以i03==i04的结果为false。
- 类型Integer和int采用进行自动拆装箱比较,而equals是比值操作,无所谓引用不引用。
总而言之:
a. 只要比较双方类型或者值有一方是基本类型,就会进行自动拆装箱比较。
b. 当类型都是Integer时,不管值是什么类型,怎样生成的,都需要注意范围-128~127;
Iterator vs Iterable
Iterable:jdk1.8源码
Iterator:jdk1.8源码
- 二者都是接口,foreach操作可用于任何实现Iterable接口的类对象,集合Collection、List、Set都是Iterable的实现类,所以他们及其他们的子类都可以使用for循环增强进行迭代;
- 通过源码可看到,Iterable调用Iterator()方法将返回一个Iterator对象。而实现了Iterator接口的对象在不同方法间进行传递的时候,由于当前迭代位置不可知,所以next()的结果也不可知。除非再为Iterator接口添加一个reset()方法,用来重置当前迭代位置。
- 实现Iterable接口的对象则不然:
func(A){
A.Iterator()
}
每次调用都返回一个从头开始的迭代器,各个迭代器之间互不影响。 - 在jdk1.8中可看到,Iterable多了两个default具体方法12345678910111213141516/**** 为了Lambda操作* items.forEach(k -> System.out.println("Item:"+k));**/default void forEach(Consumer<? super T> action) {Objects.requireNonNull(action);for (T t : this) {action.accept(t);}}// Spliterator(splitable iterator可分割迭代器)接口是Java为了并行遍历数据源中的元素而设计的迭代器default Spliterator<T> spliterator() {return Spliterators.spliteratorUnknownSize(iterator(), 0);}
Object
JDK7中所有方法
clone,equals,finalize,getClass,notify,notifyAll,hashCode,toString,waitfinalize():
一旦垃圾回收器准备好释放对象占用的存储空间,GC会判断该对象是否覆盖了finalize方法,若未覆盖,直接回收;若覆盖,将对象放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。并且在下一次垃圾回收动作发生时,如果对象还没复活,才会真正回收对象占用的内存。基本类型不是扩展于Object类,而数组类型[]是;
- Objects.equals(a,b)可以防止一方为null的情况,使用a.equals(b)前提是a!=null;
- 一般而言,继承Object重写equals需重写hashCode()方法,这是一种常规协定,可参考hashMap原理理解为什么;(参考Java核心技术卷I第9版, 5.2.3)
IntHolder
Integer与int一样,在方法参数中属于按值传递,而Integer对象不可变,因此包装器内容不会变。假如想编写一个修改数据值参数的方法就需要使用持有者类型。
String
引用
对Java中的一个变量引用一个字符串时,可能创建对象:
- 如果”ABC”这个字符串在java String池里不存在,会在java String池创建这个一个String对象;
- 如果存在,变量直接引用这个String池里的对象,因为String是final的,可以共用。
- 举个说明
|
|
- a和b都是字符串常量,所以在编译期就被确定了,c中有个b是引用不是字符串常量所以不会在编译期确定,因此前者false后者true;
- e会在java heap先创建一个String对象,如果”ABC”这个字符串在java String池里不存在,则在String池中再新建一个【疑问】
String.intern()
String.intern()方法是native方法,用来检测在String pool是否已经有这个String存在,java1.7介绍道:
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
All literal strings and string-valued constant expressions are interned. String literals are defined in section 3.10.5 of the The Java™ Language Specification.
Returns:
a string that has the same contents as this string, but is guaranteed to be from a pool of unique strings.参考美团技术团队一篇文章
http://tech.meituan.com/in_depth_understanding_string_intern.htmlJAVA 使用 jni 调用c++实现的StringTable的intern方法,StringTable的intern方法跟Java中的HashMap的实现是差不多的, 只是不能自动扩容。默认大小是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降,可参考本文HashMap介绍。
intern()的实现
JDK1.6和JDK1.7实现不同,为了避免干扰,我们主要关心1.7以后的。jdk7的版本中,字符串常量池从Perm区移到正常的Java Heap区域了,jdk8直接取消了Perm区,详情参考Java高级篇;下面通过例子说明一下。1234567891011121314151617String s = new String("1"); //生成了2个对象,常量池中的“1” 和JAVA Heap中的字符串对象s.intern(); //s对象去常量池中寻找后发现 “1” 已经在常量池里了String s2 = "1"; //生成一个s2的引用指向常量池中的“1”对象System.out.println(s == s2); // false,Object和引用相比,不相等s = s.intern();System.out.println(s == s2); // true//生成字符串常量池中的“1”和JAVA Heap中的s3引用指向的对象StringObj(其实还有两个匿名对象,不过已经失去引用)//此时s3引用对象内容是"11",但此时常量池中是没有 “11”对象的。String s3 = new String("1") + new String("1");s3.intern(); //将s3中的“11”字符串放入String常量池中,现在s3间接指向了“11”// 下图应该有误,经过intern之后,jdk7能使s3直接指向常量池,不经过StringObjString s4 = "11"; //创建的时候发现已经有这个对象了System.out.println(s3 == s4); //falses3 = s3.intern();System.out.println(s3 == s4); //true

String、StringBuffer、StringBuilder
- 可变与不可变
- String内部采用final,所以是不可变的;
- StringBuilder与StringBuffer可变;
- 是否多线程安全
- String内部是常量,所以是线程安全的;
- StringBuilder并没有加同步的操作,不是线程安全的;
- StringBuffer操作加了内置同步锁,因而是线程安全的;
final的常见使用场景
final class
- 阻止被继承,其中方法将自动转为final,域不会自动转;
- 不能修饰接口,抽象类,原因显而易见,二者都是需要“继承”来发挥作用;
final method
- 阻止继承之后的重写,不允许子类插手一些重要的处理,因此该方法就“失去虚拟特征”,意义:
没有动态绑定 ——> 编译器优化为内联函数 ——> 例如(e.getName转为e.name)
拓展:虚拟机中的即时编译器处理能力不断增强,如果方法很简短,被频繁调用且没有真正地被覆盖(如经常调用父类的方法),则即时编译器就会将这个方法进行内联处理。而如果子类这里被JVM加载进来,覆盖了内联方法,优化器将取消内联,这个过程很慢,但很少发生,所以即时编译器还是很高效的。
final variable
final变量的值只能在构造函数中赋值或初始化时定好。
Java中的编码
Java一律采用Unicode编码方式,每个字符无论中文还是英文字符都占用2个字节;
123456char han = '永';System.out.format("%x",(short)han);//对第二个参数(短整型)格式化为十六进制输出,0x开头//输出6c38char han1 = 0x6c38;System.out.println(han1);//输出永GBK–>UTF-8
123dst = new string (src,"GBK").getbytes("UTF-8")// ordst = new String(src.getBytes("GBK"),"UTF-8")
面向对象的五大基本原则
- 单一职责原则(SRP)
- 开放封闭原则(OCP)
- 里氏替换原则(LSP)
- 依赖倒置原则(DIP)
- 接口隔离原则(ISP)
基本数据类型的转换问题
例1
12short a = 128;// 00000000 10000000byte b = (byte) a; // b = -128(后8位)例2
10原码: 0000000000000000,0000000000001010;
-10补码:1111111111111111,1111111111110110(取反再+1)
因此 ~10 =
1111111111111111,1111111111110101,减1再取反后31位得-11
所以 ~10 = -11例3
==号,低精度自动转为高精度比较,如long与float,会自动转为float,+-*/亦然。低———————————————>高
byte,short,char-> int -> long -> float -> double
高到低需要强制转换,如:
int aa = (int)4.0;switch
参数是只能放int,String类型,但是放byte,short,char类型的也可以,是因为byte,short,shar可以自动提升(自动类型转换)为int,也不能boolean类型,任何类型不能转换为boolean类型型,强转也不行。final相关
12345// 被fianl修饰的变量不会自动改变类型byte b1=1,b2=2,b3,b6;final byte b4=4,b5=6;b3=(b1+b2); /*语句1*/ // 错,高到低需要强制转换b6=b4+b5; /*语句2*/ // 对,b4+b5受final影响,是byte
引用类型
Java中有强引用、软引用、弱引用、虚引用这四个概念,引用类型包含在包java.lang.ref中。
强引用(StrongReference)
强引用不会被GC回收,并且在java.lang.ref里也没有实际的对应类型。举个例子来说:1Object obj = new Object();软引用(SoftReference)
软引用在JVM报告内存不足的时候才会被GC回收,否则不会回收,正是由于这种特性软引用在caching和pooling中用处广泛。软引用的用法
|
|
SoftReference 会尽可能长地保留引用直到 JVM 内存不足时才会被回收(虚拟机保证), 这一特性使得 SoftReference 非常适合缓存应用。
弱引用(WeakReference)
当GC一但发现了弱引用对象,将会释放WeakReference所引用的对象,具体来说,就是当所引用的对象在JVM内不再有强引用时, GC后weak reference将会被自动回收。虚引用(PhantomReference)
当GC一但发现了虚引用对象,将会将PhantomReference对象插入ReferenceQueue队列,而此时PhantomReference所指向的对象并没有被GC回收,而是要等到ReferenceQueue被你真正的处理后才会被回收。虚引用的用法:123456789Object obj = new Object();ReferenceQueue<Object> refQueue =new ReferenceQueue<Object>();PhantomReference<Object> phanRef =new PhantomReference<Object>(obj, refQueue);// 调用phanRef.get()不管在什么情况下永远返回nullObject objg = phanRef.get();// 如果obj被置为null,当GC发现了虚引用,GC会将phanRef插入进我们之前创建时传入的refQueue队列// 注意,此时phanRef所引用的obj对象,并没有被GC回收,在我们显式地调用refQueue.poll返回phanRef之后// 当GC第二次发现虚引用,而此时JVM将phanRef插入到refQueue会插入失败,此时GC才会对obj进行回收Reference<? extends Object> phanRefP = refQueue.poll();
反射
类型类
Object类中包含一个方法名叫getClass,利用这个方法就可以获得一个实例的类型类。类型类指的是代表一个类型的类,因为一切皆是对象,类型也不例外,在Java使用类型类来表示一个类型。所有的类型类都是Class类的实例。123456A a = new A();// print equalif(a.getClass()==A.class)System.out.println("equal");elseSystem.out.println("unequal");获取对象方法
- public Method[] getDeclaredMethods()
返回类或接口声明的所有方法,包括public, protected, default (package) 访问和private方法的Method对象,但不包括继承的方法。当然也包括它所实现接口的方法。 - public Method[] getMethods()
返回某个类的所有public方法,包括其继承类的公用方法,当然也包括它所实现接口的方法。 - 对于private方法的反射调用,会抛出IllegalAccessException,因此访问的话,需绕过安全管理器的控制:
- public Method[] getDeclaredMethods()
|
|
native方法
native方法是由另外一种语言(如c/c++,FORTRAN,汇编)实现的本地方法
- public final static native int w(); // 合法
- abstract方法不能用native来修饰,因为native暗示这些方法是有实现体的,只不过这些实现体是非java的,但是abstract却显然的指明这些方法无实现体。
泛型擦除
泛型可以说是Java中最常用的语法糖之一,因此虚拟机不支持这些语法,在编译时转化为Object,继承的时候利用桥方法动态调用,据此应考虑泛型在开发过程中的约束和局限性。一个较典型的局限性和约束是,java不支持泛型数组:
第一种编译器检测出来直接报错,第二种逃过编译器的检测,设计者必须心理有数。
不支持泛型数组的原因是,ls对象将编译为Object[],再对该变量进行各种赋值操作都将逃过编译器的捕捉,假如编译器不小心指定错了类型,例如:
在运行时才会报ClassCastException。
异常
- throwable(接口)
- Error (unchecked)
- Exception
- RuntimeException (unchecked)
- IOException (checked)
- 一般而言,对于知道怎么处理的异常需要catch(A|B e),不知道的继续向上传递,通过在函数头尾部显式throws A,B;
断言
- assert一般用于开发/测试中,当代码发布时,这些插入的检测语句将自动地移走,即类加载器将跳过断言代码;
补充
自加运算
123int i = 0;// 0 + 2int s=(i++)+(++i);关于finally
一般而言,不管采取什么操作,只要JVM在运行finally都会执行,除非执行某些操作终止JVM进程,譬如:1System.exit(0);
关于finnally的例子:
- Java标识符由数字,字母和下划线(_),美元符号($)组成
数据结构章
ArrayList
For jdk1.7 & 1.8
继承关系
|
|
几种构造函数
ArrayList()
Constructs an empty list with an initial capacity of ten.
ArrayList(Collection<? extends E> c)
Constructs a list containing the elements of the specified collection, in the order they are returned by the collection’s iterator.
ArrayList(int initialCapacity)
Constructs an empty list with the specified initial capacity.
用法要点
- ArrayList的底层是由一个Object[]数组构成的,Object[]数组,默认的长度是10 。当调用size时,计算的是逻辑长度,即“空元素不被计算”。
- java自动增加ArrayList大小的思路是:
- 向ArrayList添加对象时,原对象数目加1;
- 如果大于原底层数组长度,则以适当长度(50%+1)新建一个原数组的拷贝,并修改原数组,指向这个新建数组;
- 原数组自动抛弃(java垃圾回收机制会自动回收);
- size则在向数组添加对象后,自增1;
- ArrayList扩容通过ensureCapacity判断后可扩容50%+1,Vector是默认扩展1倍。
- ArrayList()构造一个空列表,在添加第一个元素时,会自动扩展。而对于new ArrayList(20)则没有进行扩容行为;
同步方法
|
|
CopyOnWriteArrayList
顾名思义,写时复制,写数组时,先复制一份出来,然后向新的容器里添加元素,可以做到安全地进行并发读。因为写的时候有加锁(源码)并且不改变旧内存,再将原容器的引用指向新的容器,因此多线程写是同步的。通过读写分离实现安全的优点,适合使用在读操作远远大于写操作的场景(与volatile类似),如缓存。
缺点:
- 内存占用问题
进行写操作时(如add),内存中驻留两个对象内存,可能造成频繁的GC; - 数据一致性问题
只能保证数据的最终一致性,不能保证实时一致性。
HashMap
结构
在jdk1.7中,是数组(单位称为桶)与链表(jdk1.8中改为基于红黑树的实现)的结合体。
链表的基本元素Entry,内部类有key,value,hash和next四个字段,其中next也是一个Entry类型。
操作
- 默认的负载因子大小为0.75,当一个map填满了75%的bucket时候,将会创建原来HashMap大小的2倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。拓展,为什么HashMap初始化的大小需要2的指数次幂:参考
再查找哈希表的内在位置时[0,length-1]有个如下的操作,从而确定h所在的位置(笔者认为觉得这是寻找桶时候的类似开放定址法的实现),这样相比不是2^n-1的全111……求余而言,需要自己去实现求余,会比较高效。
|
|
- HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。
- 当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。
- 当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。
HashMap vs HashSet
HashSet是基于HashMap实现的,HashSet底层采用 HashMap 来保存所有元素,所有放入HashSet中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap的value则存储了一个公共的PRESENT对象,它是一个静态的Object对象。如添加操作:
HashMap vs HashTable
Hashtable是线程安全的,通过synchronized保证线程安全,并且是安全失败的。
- Java快速失败与安全失败迭代器 :
java迭代器提供了遍历集合对象的功能,集合返回的迭代器有快速失败型的也有安全失败型的,快速失败迭代器在迭代时如果集合类被修改,立即抛出ConcurrentModificationException异常,而安全失败迭代器不会抛出异常,因为它是在集合类的克隆对象上操作的。ArrayList,Vector,HashMap等集合返回的迭代器都是快速失败类型的。而对于Hashtable而言:the iterator in Hashtable is fail-fast but the enumerator is not fail-safe. 参考:stackoverflow
- Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
- Java快速失败与安全失败迭代器 :
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值,而且用与代替求模,如上操作中代码所示。
HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap数组table的长度length大小必须为2的n次方,而size默认大小是16,size和扩容后一定是原来2的指数,默认是2倍。
HashMap可以接受null键值和值,而Hashtable则不能;
HashMap vs ConcurrentHashMap
- ConcurrentHashMap允许多个修改操作并发进行,是线程安全的;
- HashMap在每个链表节点中储存键值对对象(Entry对象)。链表中next不是final,所以支持往后插入。然而,HashMap在多线程情况下rehash可能出现环形链表。
参考:HashMap多线程并发问题分析
参考:关于HashMap的经典面试题
ConcurrentHashMap
段数量
默认有16个,最大个数为1 << 16= 65536
实现线程安全
HashTable是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占,线程竞争激烈的情况下HashTable的效率非常低下。而对于ConcurrentHashMap:
- ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。
- ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的Hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。只有对全局需要改变时锁定的是所有的segment,如size()。
- 对于一个key,需要经过三次hash操作(哪个段,哪个桶,链表哪一位),才能最终定位这个元素的位置。
基本实现图如下【jdk1.7】

在散列时如果产生“碰撞”,将采用“分离链接法”来处理“碰撞”:把“碰撞”的 HashEntry 对象链接成一个链表。由于 HashEntry 的 next 域为 final 型,所以新节点只能在链表的表头处插入。
参考:ConcurrentHashMap高并发性的实现机制ConcurrentHashMap1.6使用的是Segement(继承自ReentrantLock)分段锁的技术来保证同步的,使用synchronized关键字保证线程安全的是HashTable。1.8之后ConcurrentHashMap改变了实现方式,将原来的Segment用单向链表来替代,put的时候对目标链表的头节点加锁,而这时用的就是synchronized。
ConcurrentHashMap1.6使用的是Segement(继承自ReentrantLock)分段锁的技术来保证同步的,使用synchronized关键字保证线程安全的是HashTable。1.8之后ConcurrentHashMap改变了实现方式,将原来的Segment(table)用单向链表来替代,put的时候对目标链表的头节点加锁,而这时用的也是synchronized。
效率:System.arraycopy > System.copyOf(本质上新建了数组,并调用了前者) > for循环
集合框架篇
安全的集合: ArrayList,Vector,HashMap等集合返回的迭代器都是快速失败类型的。通过抛出ConCurrenceModificationException的异常保证安全。
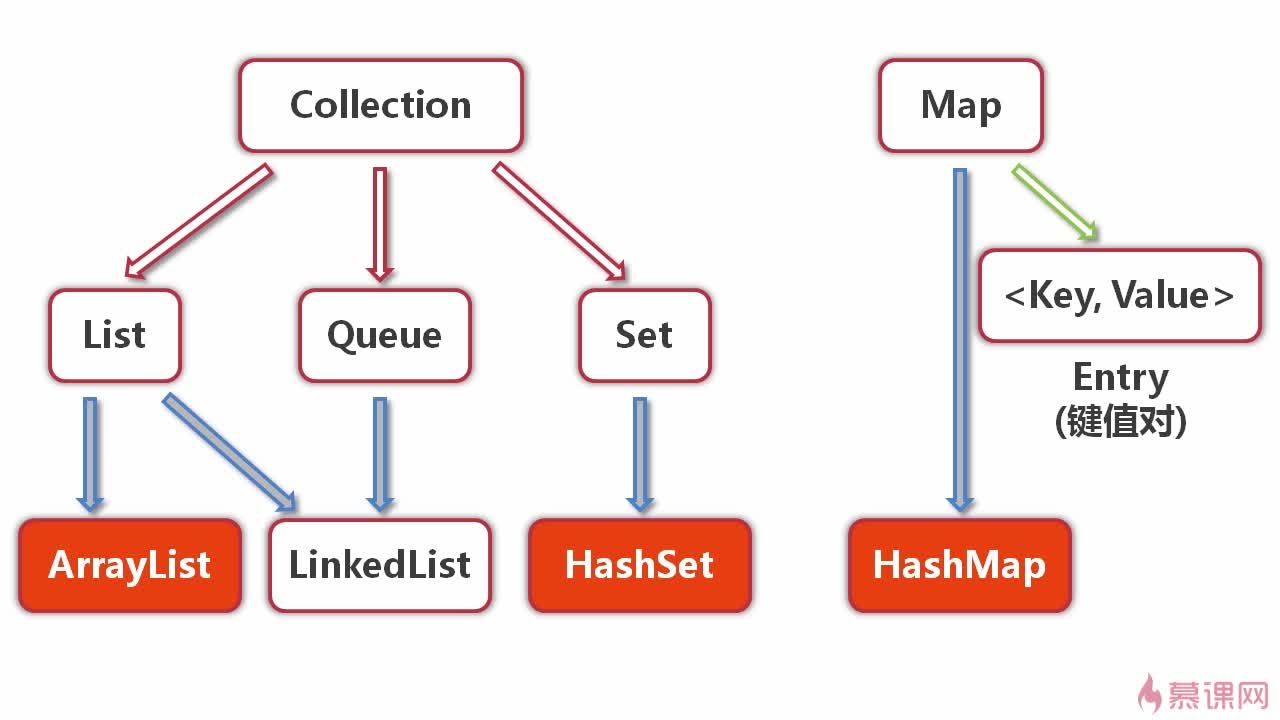
常用对象分类
Collection
- List
- LinkedList
内在为链表实现,插入,删除效率高于ArrayList - ArrayList
底层为数组实现,每次扩容都需要把整个数据复制 - Vector (安全,但已经很少使用了)
- Stack (安全)
- LinkedList
- Set
- TreeSet
插入时按照红黑树排序,速率相比普通Set会慢一些,时间复杂度为log2N - HashSet
set的常用对象
- TreeSet
- Queue
- PriorityQueue(大数据量求TopK操作)
- 迭代器非按照元素的排列顺序排列,但remove时是按照优先级数最小的元素进行取出,即优先级最高的元素。
- 优先级队列中的元素可以按照任意的顺序插入,却总是按照升序的顺序进行检索。无论何时调用remove方法,总会获得当前优先级队列中的最小元素,但并不是对所有元素都排序。它是采用了堆(一个可以自我调整的二叉树),执行增加删除操作后,可以让最小元素移动到根。
- PriorityQueue(大数据量求TopK操作)
使用普通同步容器(Vector, Hashtable)的迭代器,也需要外部锁来保证其原子性。因为普通同步容器产生的迭代器是非线程安全的。
Map
- HashMap
分离链接法,next不是final,因此往后插入。 - TreeMap
实现了SortedMap接口,默认保证按照键的升序排列的映射表 - WeakHashMap
参考http://www.cnblogs.com/Skyar/p/5962253.html - Hashtable (安全)
HashTable中hash数组默认大小是11,增加的方式是 old*2+1,保证奇数。分离链接法、开放定址法。